


안녕하세요. 볼드나인 개발팀의 백엔드 개발자 황성현입니다.
앞서 다른 게시글들에서 저희 개발팀이 GraphQL을 사용하고 있는 부분에 대해서는 소개해 드린 적이 있습니다. 저희는 Apollo라는 라이브러리를 사용하여 서버를 구현하고 있는데요 Apollo-server의 여러 기능들 중 최근 사용하게된 APQ(Automated Persisted Query)에 대해 소개해드리고자 합니다!
APQ란 무엇일까요?
간략하게 설명하자면 클라이언트가 서버에 전체 쿼리 대신에 쿼리 해시를 전송하여 네트워크 대역폭을 줄이고 서버 부하를 낮추기 위해 설계된 기능입니다. (자세한 설명을 원하시는 분을 위한 Apollo문서링크)
저는 처음 APQ를 접했을 때 ‘아 캐싱(Caching) 비슷한 기능인가 보구나’라고 생각했습니다. 하지만 분명 캐싱과 APQ는 다릅니다!
APQ의 작동방식과 캐싱과의 차이점
APQ와 캐싱은 둘 다 네트워크 대역폭을 줄이고 서버 부하를 낮추기 위해 사용되는 기술입니다. 하지만 둘 간에는 몇가지 차이점이 있습니다.
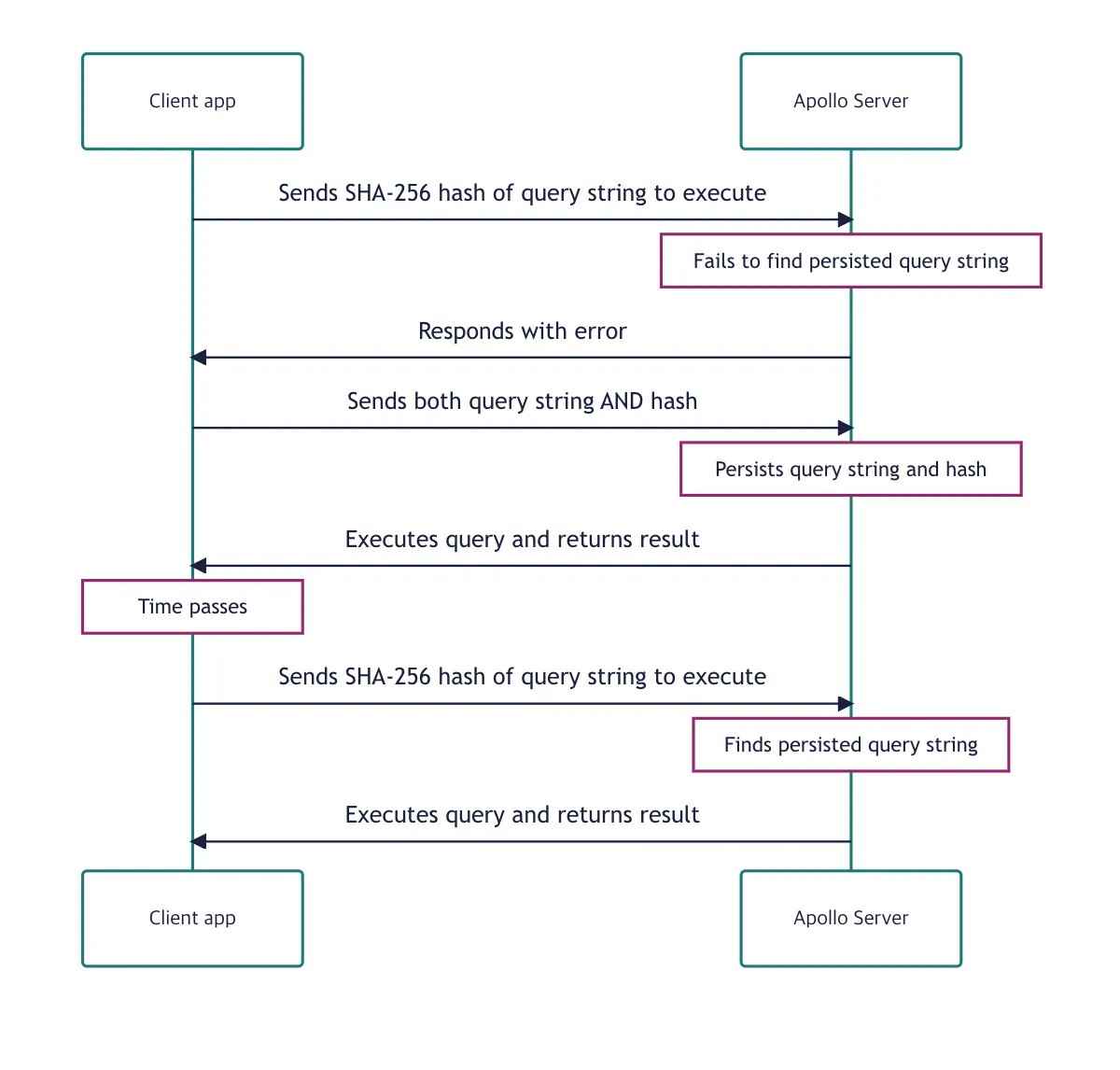
먼저, APQ는 클라이언트에서 서버로 요청을 보낼 때, 쿼리 해시를 사용하여 이 쿼리 해시와 일치하는 해시 값이 서버 측에 저장되어 있는지 확인합니다.
만약 서버에 일치하는 해시 값이 있다면 클라이언트에서 보내는 요청에는 쿼리 전문이 담겨있지 않아 좀 더 가벼운 요청을 보낼 수 있게 되고, 서버 측 또한 클라이언트가 보낸 쿼리 전문에 대한 검증 과정을 생략할 수 있게 되어 부담을 덜 수 있습니다.
서버에 일치하는 해시 값이 저장되어 있지 않다면 다시 서버 측으로부터 해당 해시값이 저장되어 있지 않다고 알려주는 응답을 받게 되고, 자동으로 다시 한번 요청을 보내게 됩니다.(이번에는 쿼리 해시 값이 아닌 쿼리 전문을 담아 보냅니다.)
캐싱은 이전에 서버에서 반환한 결과를 메모리나 디스크에 저장하고, 동일한 쿼리에 대한 요청이 올 경우 이전에 저장한 결과를 반환하는 기능입니다. 즉 APQ는 쿼리 자체를 해싱 하여 전송되는 쿼리의 크기를 줄이는 것이고, 캐싱은 결과 데이터를 저장하여 서버의 부하를 줄입니다.
클라이언트에서 보낸 요청을 통한 APQ 작동 흐름 관찰
문서와 설명으로는 APQ의 동작 방식이 잘 와닿지 않을 수 있는데요..! 직접 클라이언트가 보낸 요청을 살펴보면 좀 더 이해가 쉬울 수 있습니다.
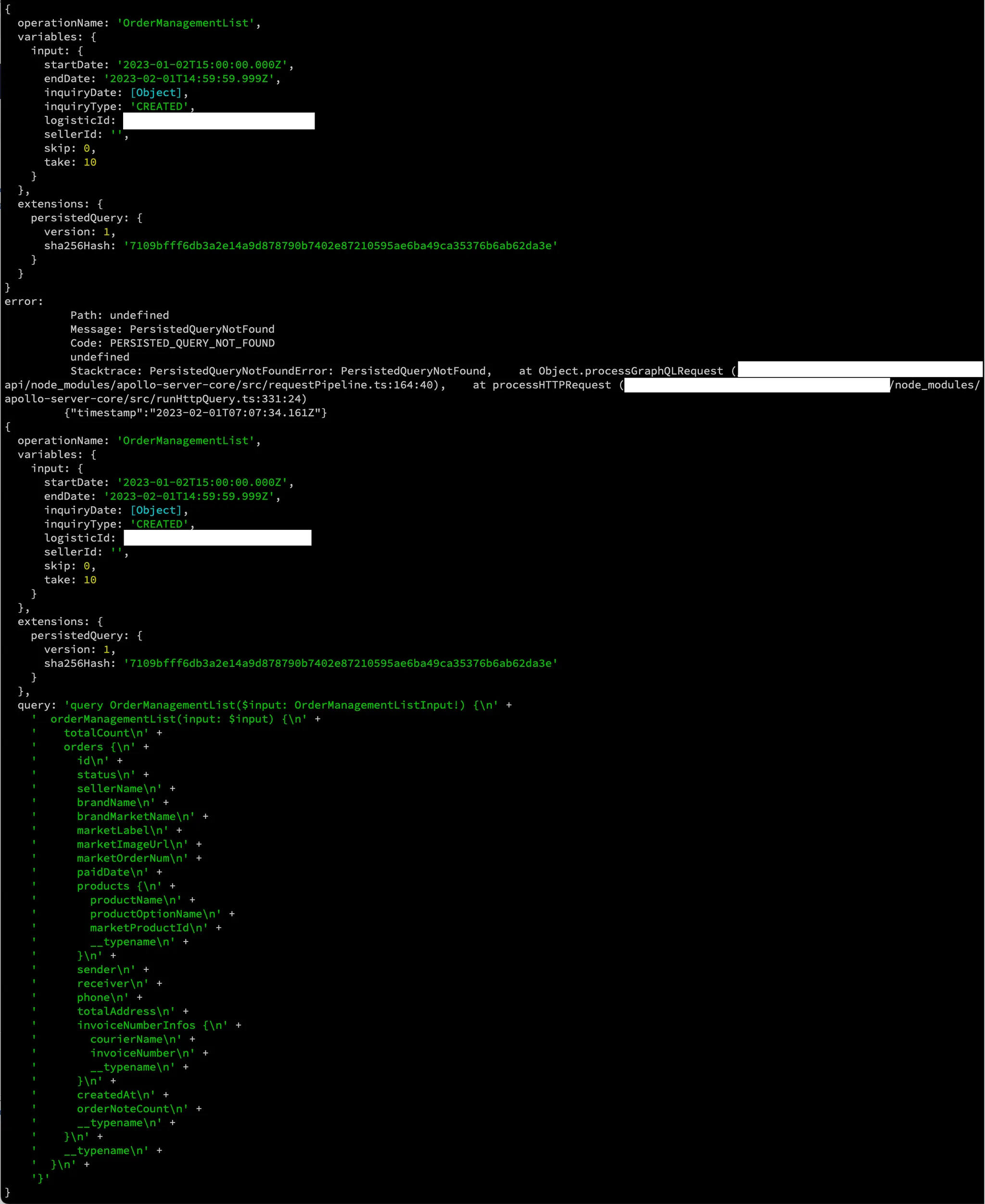
위 이미지는 APQ 도입 작업 당시에 APQ 기능 활성화 후 클라이언트에서 서버로 요청을 보냈을 때 서버에서 그 요청의 내용을 로그로 찍어본 결과입니다.
스크린샷의 내용을 간략히 설명해 드리면…
첫 줄부터 시작되는 {}안의 내용은 가장 처음 클라이언트에서 서버로 보낸 요청입니다. 이 요청을 살펴보면 query가 없고 sha256hash 값만 담겨있는 것을 볼 수 있습니다!
서버에서는 이 최초의 요청에 담긴 해시값이 서버에 저장되어 있는지 확인합니다. 위 스크린샷의 상황에서는 해당 해시값이 서버에 저장되어 있지 않아 error를 던졌습니다!(code: PERSISTED_QUERY_NOT_FOUND 가 에러 내용 중 핵심!)
클라이언트에서는 서버가 던진 해시값이 저장되어 있지 않다는 에러를 받고 곧바로 다시 요청을 보내게 됩니다.(이 재요청은 클라이언트에서 별도로 코드를 작성하는 것이 아닌 apollo 자체 기능으로 이루어집니다!) 이 요청에는 최초에 보낸 요청과는 다르게 query 전문이 포함되어 있습니다.
마치며
GraphQL 서버를 운영하다 보면 한 번쯤은 캐싱에 관한 고민에 빠지게 되는데, 아무래도 같은 Query/Mutation에 대해서도 클라이언트가 어떤 필드에 대해 질의하였는지에 따라 서버의 응답이 달라지기 때문에 캐싱 적용이 쉽지 않기 때문일 것입니다.(불가능한 것은 아닙니다!) APQ라는 기능 또한 그런 고민에서부터 출발한 기능이 아닐까 생각해 봅니다..!